The Testing Quadrant
November 27, 2018For the umpteenth time in my career, I'm trying to convince coworkers to adopt better testing strategies. Again for the umpteenth time, the main push-back is something like this.
But the tests we already have already waste my time waiting for them and debugging spurious failures and re-submitting my changes!
That's probably all true, I've felt that pain myself on many projects through the years, but it's still not going to stop me. To explain why, let's start with a diagram.
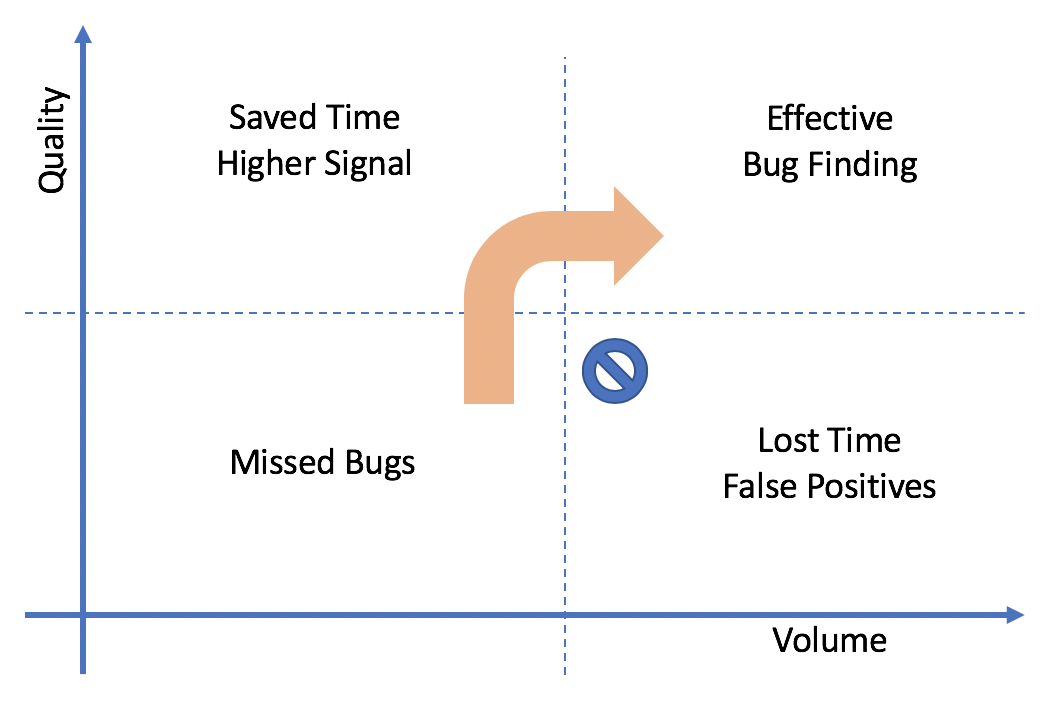
This diagram (I hope) illustrates many things. First, let's look at the lower right. This is what makes people afraid of spending time on tests, and justifiably so if they've never worked with a good test environment. Just adding more tests makes things worse if you're still below the quality mid-point. Unfortunately, this is quite often exactly what project managers and others promote as the antidote to poor quality, because it's easy to measure. It's misguided. As a developer, I hate waiting for tests. I hate debugging tests that often fail for no reason, or because they were testing implementation details and broke as a result of a perfectly valid change. Most of all, I hate spending time creating a complex mock environment that by its very nature avoids the places where real bugs live. That's all garbage. It's nothing I'd ever advocate.
What I do advocate is moving up first. Hence the orange arrow. Good tests are:
- Easy to write. This means comprehensive and well-documented ways of setting up a scenario, triggering actions, examining results, injecting errors, etc. These are all very specific to the software you're testing, but they're absolutely essential.
- Easy and quick to run. A particular problem here is tests that have to wait for some periodic task to run and do something (e.g. detect and repair a deliberately corrupted file). Sure, intervals can be tuned down for testing, but that usually only gets you so far before it starts causing spurious failures and you're back in the bottom right quadrant. Relying too much on the passage of time instead of occurrence of events is a distributed system anti-pattern for this and many other reasons. When it's unavoidable, or just too hard to change, I have some ideas for how to deal with it in testing but I'll save that for another day.
- Realistic. This means testing the total effect of real externally-driven requests (e.g. reads and writes for a storage system). That includes all explicit messaging between components to satisfy those requests, all implicit communication/coordination (e.g. via transient changes to a shared lock/lease service or database), and all changes made to persistent state by any involved component. For 95% of tests this doesn't need to be a physically real environment, it's safe to factor out things like actual network interfaces, but the realism of requests and results still has to be there.
- High signal. Nobody likes a test that constantly sends up false alarms. Whatever tests you have - few or many, long or short, deep or shallow - a failure should actually mean something worth paying attention to.
It's OK to have relatively few tests initially that meet these standards. Better to stay in the lower left quadrant than move to the lower right. Once the infrastructure and culture for good testing exist, once people are comfortable writing high-quality tests and trust those to do what tests should do, then it's time to start making them more comprehensive. Developing a strong test suite requires high skill and often takes years, but it ultimately pays for itself in increased development velocity. It's easier to "be bold" and "move fast" when you don't have to spend half your time chasing "spooky behavior" in production (or even full-scale system tests). Maybe finding those same problems via targeted, deterministic, quick-to-run tests earlier in the development process doesn't feel as heroic, but when it comes to running a business I'll choose diligence over heroism every time.
